
I am currently a research scientist at Magic Leap.
I received my Ph.D. from the University of California, San Diego (UCSD) in Computer Science and Engineering studying computer vision, where I was advised by Profs David Kriegman and Ravi Ramamoorthi.
I received my Bachelor of Science degree in Intensive Mathematics and Computer Science from Yale University in 2011. I also took many upper division physics, chemistry, and biology courses.
Email: z...@cs.ucsd.edu
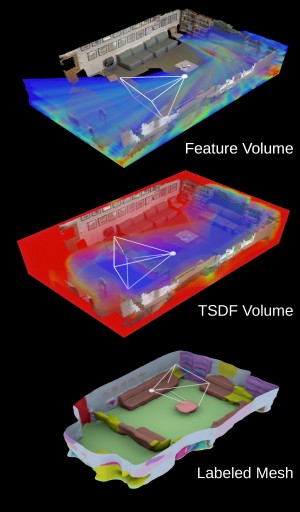
Atlas: End-to-End 3D Scene Reconstruction from Posed Images
Zak Murez, Tarrence van As, James Bartolozzi, Ayan Sinha, Vijay Badrinarayanan, Andrew Rabinovich
ECCV
2020
Project |
Paper |
Code |
Video
Abstract: We present an end-to-end 3D reconstruction method for a scene by directly regressing a truncated signed distance function (TSDF) from a set of posed RGB images. Traditional approaches to 3D reconstruction rely on an intermediate representation of depth maps prior to estimating a full 3D model of a scene. We hypothesize that a direct regression to 3D is more effective. A 2D CNN extracts features from each image independently which are then back-projected and accumulated into a voxel volume using the camera intrinsics and extrinsics. After accumulation, a 3D CNN refines the accumulated features and predicts the TSDF values. Additionally, semantic segmentation of the 3D model is obtained without significant computation. This approach is evaluated on the Scannet dataset where we significantly outperform state-of-the-art baselines (deep multiview stereo followed by traditional TSDF fusion) both quantitatively and qualitatively. We compare our 3D semantic segmentation to prior methods that use a depth sensor since no previous work attempts the problem with only RGB input.

Image to Image Translation for Domain Adaptation
Zak Murez, Soheil Kolouri, David Kriegman, Ravi Ramamoorthi, Kyungnam Kim
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2018
Paper
Abstract: We propose a general framework for unsupervised domain adaptation, which allows deep neural networks trained on a source domain to be tested on a different target domain without requiring any training annotations in the target domain. This is achieved by adding extra networks and losses that help regularize the features extracted by the backbone encoder network. To this end we propose the novel use of the recently proposed unpaired image-toimage translation framework to constrain the features extracted by the encoder network. Specifically, we require that the features extracted are able to reconstruct the images in both domains. In addition we require that the distribution of features extracted from images in the two domains are indistinguishable. Many recent works can be seen as specific cases of our general framework. We apply our method for domain adaptation between MNIST, USPS, and SVHN datasets, and Amazon, Webcam and DSLR Office datasets in classification tasks, and also between GTA5 and Cityscapes datasets for a segmentation task. We demonstrate state of the art performance on each of these datasets.

Learning to See through Turbulent Water
Zhengqin Li, Zak Murez, David Kriegman, Ravi Ramamoorthi, Manmohan Chandraker
IEEE Winter Conf. on Applications of Computer Vision (WACV)
2018
Paper
| Code
| Data
Abstract: Imaging through dynamic refractive media, such as looking into turbulent water, or through hot air, is challenging since light rays are bent by unknown amounts leading to complex geometric distortions. Inverting these distortions and recovering high quality images is an inherently ill-posed problem, leading previous works to require extra information such as high frame-rate video or a template image, which limits their applicability in practice. This paper proposes training a deep convolution neural network to undistort dynamic refractive effects using only a single image. The neural network is able to solve this ill-posed problem by learning image priors as well as distortion priors. Our network consists of two parts, a warping net to remove geometric distortion and a color predictor net to further refine the restoration. Adversarial loss is used to achieve better visual quality and help the network hallucinate missing and blurred information. To train our network, we collect a large training set of images distorted by a turbulent water surface. Unlike prior works on water undistortion, our method is trained end-to-end only requires a single image and does not use a ground truth template at test time. Experiments show that by exploiting the structure of the problem, our network outperforms state-of-the-art deep image to image translation.
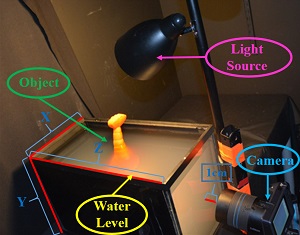
Depth and Image Restoration from Light Field In a Scattering Medium
Jiandong Tian, Zak Murez, Tong Cui, Zhen Zhang, David Kriegman, Ravi Ramamoorthi
IEEE International Conference on Computer Vision (ICCV)
2017
Paper
Abstract: Traditional imaging methods and computer vision algorithms are often ineffective when images are acquired in scattering media, such as underwater, fog, and biological tissue. Here, we explore the use of light field imaging and algorithms for image restoration and depth estimation that address the image degradation from the medium. Towards this end, we make the following three contributions. First, we present a new single image restoration algorithm which removes backscatter and attenuation from images better than existing methods do, and apply it to each view in the light field. Second, we combine a novel transmission based depth cue with existing correspondence and defocus cues to improve light field depth estimation. In densely scattering media, our transmission depth cue is critical for depth estimation since the images have low signal to noise ratios which significantly degrades the performance of the correspondence and defocus cues. Finally, we propose shearing and refocusing multiple views of the light field to recover a single image of higher quality than what is possible from a single view. We demonstrate the benefits of our method through extensive experimental results in a water tank.
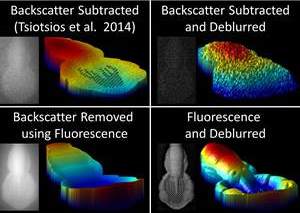
Photometric Stereo in a Scattering Medium
Zak Murez, Tali Treibitz, Ravi Ramamoorthi, and David Kriegman
International Conference on Computer Vision (ICCV)
2015
Paper |
Video
Abstract: Photometric stereo is widely used for 3D reconstruction. However, its use in scattering media such as water, biological tissue and fog has been limited until now, because of forward scattered light from both the source and object, as well as light scattered back from the medium (backscatter). Here we make three contributions to address the key modes of light propagation, under the common single scattering assumption for dilute media. First, we show through extensive simulations that single-scattered light from a source can be approximated by a point light source with a single direction. This alleviates the need to handle light source blur explicitly. Next, we model the blur due to the scattering of light from the object. We measure the object point-spread function and introduce a simple deconvolution method. Finally, we show how imaging fluorescence emission where available eliminates the backscatter component and increases the signal-to-noise ratio. Experimental results in a water tank, with different concentrations of scattering media added, show that deconvolution produces higher-quality 3D reconstructions than previous techniques, and that when combined with fluorescence, can produce results similar to that in clear water even for highly turbid media.

Maximizing the potential of electron cryomicroscopy data collected using direct detectors
David Veesler, Melody G Campbell, Anchi Cheng, Chi-yu Fu, Zachary Murez, John E Johnson, Clinton S Potter, Bridget Carragher
Journal of Structural Biology (JSB)
2013
Paper
Abstract: Single-particle electron cryo-microscopy is undergoing a technical revolution due to the recent developments of direct detectors. These new recording devices detect electrons directly (i.e. without conversion into light) and feature significantly improved detective quantum efficiencies and readout rates as compared to photographic films or CCDs. We evaluated here the potential of one such detector (Gatan K2 Summit) to enable the achievement of near-atomic resolution reconstructions of biological specimens when coupled to a widely used, mid-range transmission electron microscope (FEI TF20 Twin). Compensating for beam-induced motion and stage drift provided a 4.4 Å resolution map of Sulfolobus Turreted Icosahedral Virus (STIV), which we used as a test particle in this study. Several motion correction and dose fractionation procedures were explored and we describe their influence on the resolution of the final reconstruction. We also compared the quality of this data to that collected with a FEI Titan Krios microscope equipped with a Falcon I direct detector, which provides a benchmark for data collected using a high-end electron microscope.
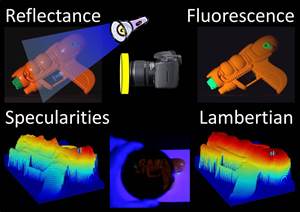
Shape From Fluorescence
Tali Treibitz, Zak Murez, B. Greg Mitchell, and David Kriegman
European Conference on Computer Vision (ECCV)
2012
Paper |
Video
Abstract: Beyond day glow highlighters and psychedelic black light posters, it has been estimated that fluorescence is a property exhibited by 20% of objects. When a fluorescent material is illuminated with a short wavelength light, it re-emits light at a longer wavelength isotropically in a similar manner as a Lambertian surface reflects light. This hitherto neglected property opens the doors to using fluorescence to reconstruct 3D shape with some of the same techniques as for Lambertian surfaces – even when the surface’s reflectance is highly non-Lambertian. Thus, performing reconstruction using fluorescence has advantages over purely Lambertian surfaces. Single image shape-from-shading and calibrated Lambertian photometric stereo can be applied to fluorescence images to reveal 3D shape. When performing uncalibrated photometric stereo, both fluorescence and reflectance can be used to recover Euclidean shape and resolve the generalized bas relief ambiguity. Finally for objects that fluoresce in wavelengths distinct from their reflectance (such as plants and vegetables), reconstructions do not suffer from problems due to inter-reflections. We validate these claims through experiments.
More personal stuff




